


Video copy detection - Benchmark
The benchmarking process
Two benchmarks have been done, one from YouTube, another from MUSCLE-VCD-2007 challenge.
Benchmarks compare the result of different softwares (Duplicate Media Finder™, Duplicate Video Search, Video Comparer) and publications.
The measures:
- The percent of positive duplicates found
- The speed of the analysis (the total duration of videos divided by the analysis duration)
Computer specifications
Processor : Intel Core i7-2600K @ 3.40GHz
Memory : 8GB
Hard drive : 2TB 7200rpm Raid0
Operating system : 64-bit Windows 8.1
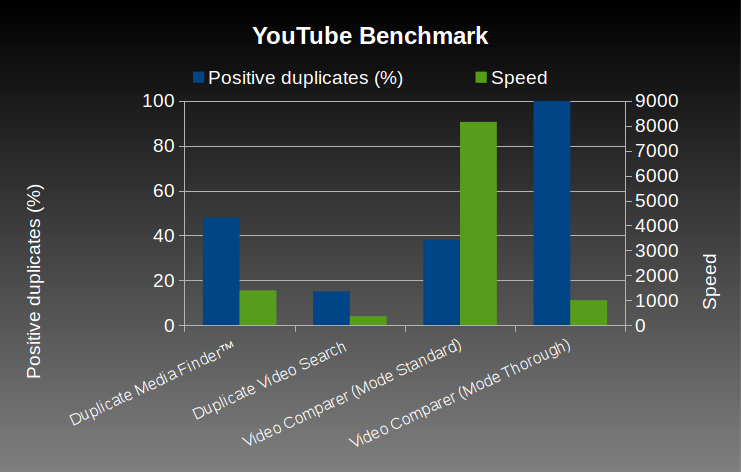
YouTube Benchmark
The videos used for this benchmark have been downloaded from YouTube. This database contains 102 video clips of a total length equal to about 61 hours. The content of these videos are very various (cartoons, old movies, short movie trailers, sports). The source of video pairs is the same, but the image format, codec, time offset, duration, may change.
Softwares parameters:
- Duplicate Media Finder™ (6.005): Video files, Default level of sensitivity.
- Duplicate Video Search (2.1): Video indexing to 100s, Max shift to 30s.
- Video Comparer (1.07.000): Standard & Thorough scan mode.
Reference:
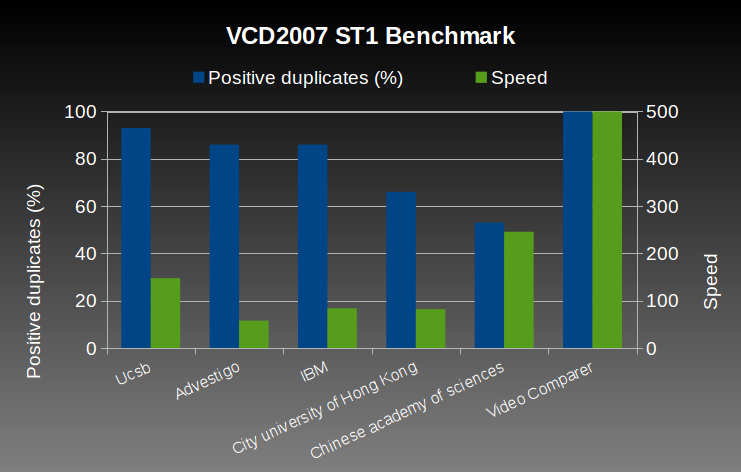
VCD2007 ST1 Benchmark
The video database used for this benchmark is MUSCLE-VCD-2007. This database is very interesting for performance comparison, because many teams have developed algorithms and published their results.
The process involves two phases:
- The large database DB-MPEG1 is learned. This database contains 101 video clips of a total length equal to about 80 hours. These video clips come from several different sources such as the web video clips, TV programs and movies. They cover a wide range of categories, including movies, commercials, sports games, cartoons, etc.
- The query database ST1Queries is processed. There are 15 query video clips with a total length a little more than 3 hours. Ten query video clips are attacked by one or more changes, or transformations while the remaining five video clips were not from the database. The transformations includes re-encoded, noised, or slightly re-edited.
References:
http://www-rocq.inria.fr/imedia/civr-bench/data.html (web.archive.org)
http://lbmedia.ece.ucsb.edu/resources/ref/lsmm2009.pdf (web.archive.org)